
Python学習の一環としてブログ記事の文字数カウントプログラムを作ってみました。
作成したプログラムは、ブログのXMLサイトマップから記事のURLを抽出し、各記事の文字数をカウントしてCSVファイルに出力するというものです。
本記事では作成したプログラムの紹介とコードの説明をしていきます。
作成した文字数カウントプログラム
作成したプログラムのコードは以下の通りです。
import csv
import re
import requests
from bs4 import BeautifulSoup
from time import sleep
#対象サイトのsitemap.xmlを指定#
url = 'ターゲットサイトのURL'
response = requests.get(url+'sitemap.xml')
result = response.content
#sitemap.xmlからURL一覧を取得#
soup_sitemap = BeautifulSoup(result, 'html.parser')
loc_list = soup_sitemap.select('loc')
url_list = []
for xmls in loc_list:
response_xml = requests.get(re.sub('<[a-z]>', '', xmls.text))
result_xml = response_xml.content
bs_xml = BeautifulSoup(result_xml, 'html.parser')
loc_list_url = bs_xml.select('loc')
for loc_url in loc_list_url:
url_list.append(re.sub('<[a-z]>', '', loc_url.text))
sleep(3)
#記事以外のURLを削除#
url_list.remove(url)
article_url_list = [s for s in url_list if url+'category/' not in s]
#各記事の情報取得およびCSV出力#
with open('article_data.csv', 'w', newline="") as d:
writer = csv.writer(d)
writer.writerow(['記事タイトル', 'URL', '文字数'])
for article_url in article_url_list:
response_article_url = requests.get(article_url)
result_article_url = response_article_url.content
#記事内容の抽出#
soup_article = BeautifulSoup(result_article_url, 'html.parser')
title = soup_article.title.string
print(title)
element = soup_article.find("article")
print(article_url)
article = element.get_text()
print('文字数:' + str(len(article)))
writer.writerow([title, article_url, len(article)])
sleep(3)今回はBeautifulSoupを使ってXMLおよびHTMLからデータを抽出しました。
9行目のターゲットサイトのURLと書かれているところにURLを入れると、そのサイトのXMLサイトマップに載っている記事の情報を取得できるようになっています。
当ブログ用に作成したものであるため、他サイトでも正常に動作するかはわかりません。ただ、プラグイン「XML sitemaps」でサイトマップを作成しているブログなら、大きな修正なく使えるのではないかと思います。
出力はCSVファイルで、その内容は記事タイトル、記事URLおよび文字数となっています。
コードの説明
以下、コードの説明をしていきます。
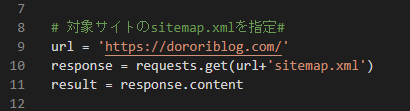
対象サイトのsitemap.xmlを指定
url = 'ターゲットサイトのURL'
response = requests.get(url+'sitemap.xml')
result = response.contentターゲットサイトのURLにsitemap.xmlを連結することで、XMLサイトマップのURLを作り、情報を取得します。
sitemap.xmlからURL一覧を取得
soup_sitemap = BeautifulSoup(result, 'html.parser')
loc_list = soup_sitemap.select('loc')
url_list = []
for xmls in loc_list:
response_xml = requests.get(re.sub('<[a-z]>', '', xmls.text))
result_xml = response_xml.content
bs_xml = BeautifulSoup(result_xml, 'html.parser')
loc_list_url = bs_xml.select('loc')
for loc_url in loc_list_url:
url_list.append(re.sub('<[a-z]>', '', loc_url.text))
sleep(3)for文を使って記事のURLを1つずつurl_listに格納しています。その際にre.sub(‘<[a-z]>’, ”, loc_url.text)で不要なタグを削除しています。
連続してページにアクセスするのでfor文の終わりにsleepで3秒間の処理停止時間を入れています。
記事以外のURLを削除
url_list.remove(url)
article_url_list = [s for s in url_list if url+'category/' not in s]取得してきたURLの中から記事以外のURLを削除しています。ここではまずトップページのURLを削除してから、カテゴリーページのURLを削除しています。
各記事の情報取得およびCSV出力
with open('article_data.csv', 'w', newline="") as d:
writer = csv.writer(d)
writer.writerow(['記事タイトル', 'URL', '文字数'])
for article_url in article_url_list:
response_article_url = requests.get(article_url)
result_article_url = response_article_url.content
#記事内容の抽出#
soup_article = BeautifulSoup(result_article_url, 'html.parser')
title = soup_article.title.string
print(title)
element = soup_article.find("article")
print(article_url)
article = element.get_text()
print('文字数:' + str(len(article)))
writer.writerow([title, article_url, len(article)])
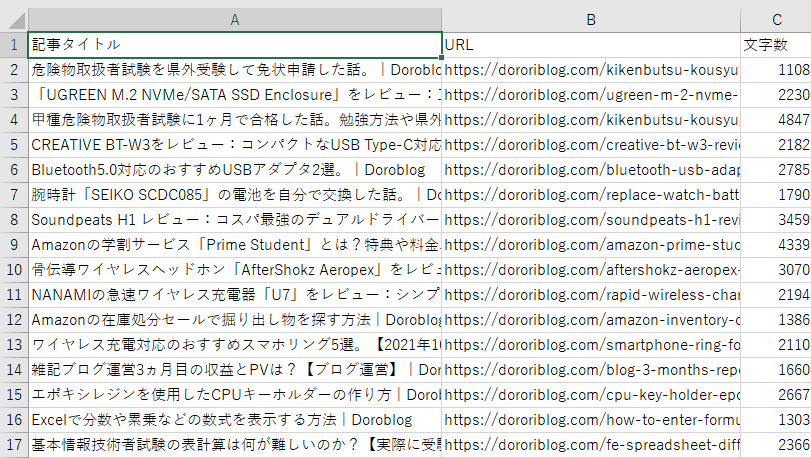
sleep(3)ファイル「article_data.csv」に情報を書き出しています。1行目に「記事タイトル、URL、文字数」と記載し、2行目から記事の情報を入れています。今回はarticle要素内の全文字数をカウントしています。
コードの1行目にあるnewline=””は、不要な改行が入り空白の行ができるのを防ぐために記述しています。printは処理がどこまで進んでいるのか確認するために入れているだけなので、消してしまってもCSVファイルへの書き出しに支障はありません。
さいごに
今回作成したプログラムは「記事タイトル、URL、文字数」をCSVファイルに書き出すだけでしたが、広告リンク数や画像数、アクセス数などを一緒に取得すればアクセス傾向の分析に役立つかもしれません。
Pythonってすごい言語ですね。初心者でも簡単に動くものが作れるので、プログラミング学習が楽しくなります。



コメント